VIGOR: Video Geometry-Oriented Reward for Alignment
A geometry-based reward for video diffusion alignment using pointwise reprojection error, enabling post-training (SFT/DPO) and training-free test-time scaling.
Paper: arXiv:2603.16271 | Project Page: vigor-geometry-reward.com
Authors: Tengjiao Yin, Jinglei Shi, Heng Guo, Xi Wang
Affiliations: Nankai University · Beijing University of Posts and Telecommunications · LIX, École Polytechnique, IP Paris
Abstract
Video diffusion models lack explicit geometric supervision during training, leading to inconsistency artifacts such as object deformation, spatial drift, and depth violations in generated videos. To address this, we propose VIGOR (VIdeo Geometry-Oriented Reward), a geometry-based reward model that leverages pretrained geometric foundation models to evaluate multi-view consistency through cross-frame reprojection error. Unlike previous geometric metrics that compare pixel intensity, our approach conducts error computation in a pointwise fashion in 3D space, yielding a more physically grounded and robust signal. We apply this reward through two complementary pathways: post-training via SFT/DPO, and inference-time optimization via test-time scaling.
Motivation
State-of-the-art video diffusion models — whether bidirectional or causal autoregressive — share a fundamental limitation: no explicit geometric supervision during training. Closed-source models partially compensate through massive data scale, but this remains infeasible for open-source research. The result is a class of persistent geometric artifacts:
- Object deformation — shapes change unnaturally across frames
- Spatial drift — static backgrounds shift unexpectedly
- Depth violations — objects violate perspective and occlusion consistency
- Flickering — unstable pixel-level jitter and temporal incoherence
Approaches that condition on depth maps or camera poses at training time are constrained by data accessibility — Internet-scale video corpora almost never carry such geometric annotations. VIGOR sidesteps this by framing the problem as reward-based alignment: define a reliable, annotation-free geometric signal and use it to steer existing models.
Method Overview
VIGOR consists of two components: a Geometry-Based Reward Model and a Geometry-Guided Preference Alignment procedure.
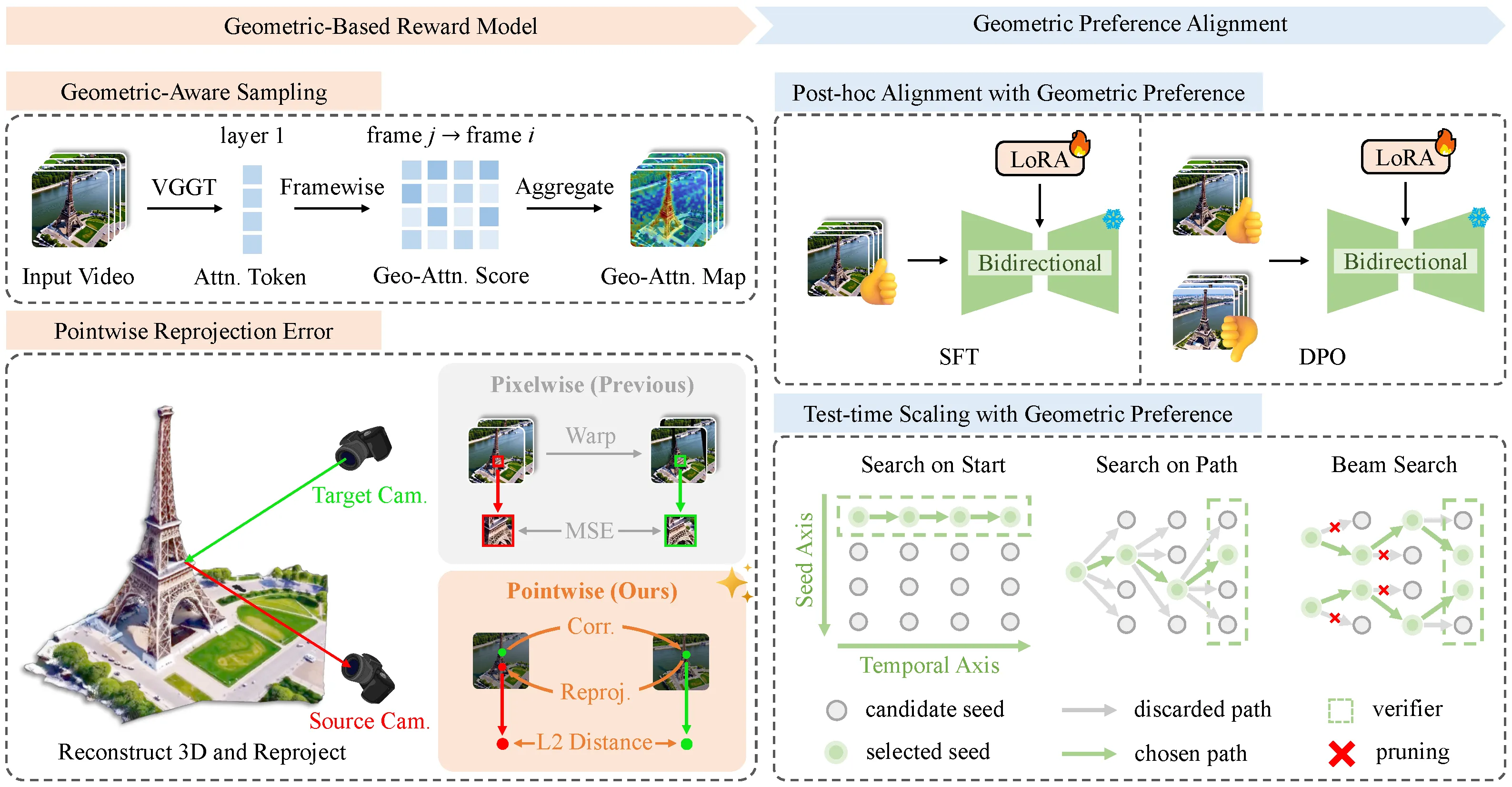
1. Geometry-Aware Sampling (GAS)
Not all image regions are equally informative for geometric evaluation. Textureless areas (sky, plain walls) produce unreliable point correspondences. VIGOR exploits an observation about VGGT (Visual Geometry Grounded Transformer, the underlying geometric foundation model): its shallow global attention layers naturally emphasize geometrically meaningful regions — object edges, corners, and texture-rich surfaces.
The algorithm extracts VGGT’s layer-1 attention scores across frames, up-samples them to a geometric attention heatmap, then partitions each frame into non-overlapping patches and selects the top-τ% by attention value. The center pixel of each selected patch becomes a sampling point. This yields a sparse but high-quality set of evaluation points concentrated on regions with reliable correspondences.
2. Pointwise Reprojection Error
For each sampled point in a reference frame, VIGOR:
- Uses a point tracker to find the corresponding location in target frames
- Uses VGGT-predicted depth and camera parameters to back-project the point to 3D world coordinates
- Re-projects the 3D point into the target frame using target camera parameters
- Computes the L2 distance between the geometry-predicted projection and the tracker-estimated correspondence
The final reward is the mean reprojection error over all valid point-frame pairs. A lower error means higher geometric consistency.
Unlike pixel-warping approaches that compare intensity values (susceptible to lighting and appearance changes), this metric operates purely in geometric position space — making it significantly more robust.
3. Geometry-Guided Preference Alignment
With a reliable reward signal, VIGOR applies it through two complementary pathways:
Post-hoc Alignment (bidirectional models)
First, a preference dataset GB3DV-25k is constructed: for each of 2,560 diverse text prompts, 10 video candidates are generated with CausVid, scored with the geometry reward, and the best/worst pair is selected. This yields 25,600 geometry-ranked video pairs covering indoor/outdoor scenes and diverse camera motions.
- SFT (Supervised Fine-Tuning): LoRA-based (rank=64, α=128) fine-tuning on high-reward samples using the flow-matching objective
- DPO (Direct Preference Optimization): Flow-DPO directly contrasts winning and losing video pairs under the Bradley-Terry model, with an auxiliary loss penalizing static motion to prevent mode collapse
Test-Time Scaling / TTS (causal autoregressive models)
No parameter updates required. The reward acts as a verifier guiding search at inference time. For causal models generating frames sequentially, VIGOR proposes three search strategies:
| Strategy | Core Idea | Complexity |
|---|---|---|
| Search on Start (SoS) | Generate S complete videos from S seeds independently; return highest-reward | O(KN) |
| Search on Path (SoP) | At each timestep, pick the best seed from S candidates within a sliding window | O(SN) |
| Beam Search (BS) | Maintain K candidate paths; expand K×S nodes per step, prune to top-K | O(KSN) |
SoS and SoP are special cases of Beam Search at (K=1,S) and (K,S=1) respectively. Beam Search combines diversity from SoS with fine-grained temporal selection from SoP.
Experiments
Reward Comparison via Best-of-N TTS (Bidirectional Model)
Evaluated on the full GB3DV-25k dataset with N=10 candidates:
| Method | PSNR↑ | SSIM↑ | LPIPS↓ | EPI↓ | VBench Total↑ |
|---|---|---|---|---|---|
| Baseline | 19.68 | 0.6381 | 0.3604 | 5.553 | 83.33 |
| Epipolar | 22.45 | 0.7557 | 0.2432 | — | 84.50 |
| Reproj-Pix | 21.07 | 0.7267 | 0.3036 | 4.549 | 83.97 |
| Reproj-Pts (Ours) | 22.66 | 0.7665 | 0.2330 | 3.442 | 84.52 |
VIGOR’s pointwise reward achieves the best scores on all 3D reconstruction metrics and the highest VBench total — demonstrating that geometric and perceptual quality are complementary, not competing.
TTS Budget Scaling (Causal Streaming Model)
Budget scaling experiments (budget 1–16) on a 16-clip subset show:
- All three search variants exhibit scaling behavior: more search budget consistently improves both geometric and perceptual metrics
- Beam Search achieves the strongest 3D reconstruction scores (largest explored search space)
- Search on Path achieves the best overall VBench score (stable per-frame optimization)
- The scaling trend confirms VIGOR’s reward provides a meaningful and consistent guidance signal
Post-hoc Alignment (Bidirectional DiT)
Applied to Wan2.1-T2V-1.3B with LoRA fine-tuning:
| Method | PSNR↑ | SSIM↑ | LPIPS↓ | EPI↓ | SC↑ | BC↑ | IQ↑ |
|---|---|---|---|---|---|---|---|
| Baseline | 22.45 | 0.7548 | 0.2243 | 2.832 | 95.98 | 94.43 | 76.30 |
| + SFT | 23.52 | 0.7927 | 0.1842 | 2.337 | 96.97 | 95.15 | 76.58 |
| + DPO (Epipolar) | 23.57 | 0.7973 | 0.1818 | 2.157 | 96.08 | 95.16 | 76.52 |
| + DPO (Reproj-Pts) | 24.54 | 0.7977 | 0.1789 | 2.127 | 97.05 | 95.25 | 76.63 |
DPO with our pointwise reward attains the best SSIM (0.7977), LPIPS (0.1789), and EPI (2.127), outperforming both the SFT baseline and the epipolar DPO variant across geometric and perceptual dimensions.
Key Contributions
Pointwise Reprojection Reward — Cross-frame geometric consistency signal computed in 3D position space, decoupled from appearance variation and more robust than pixel-space alternatives
Geometry-Aware Sampling — VGGT attention-guided region selection that filters out low-texture, non-semantic areas and focuses evaluation on geometrically meaningful regions
GB3DV-25k Dataset — 25,600 geometry-ranked preference pairs spanning diverse scenes and camera motions, enabling scalable post-hoc alignment
TTS for Causal Video Models — First study of structured inference-time search (SoS / SoP / Beam Search) on causal autoregressive video generation, showing consistent scaling behavior
Dual alignment pathways — Both parameter-updating (SFT/DPO) and parameter-free (TTS) methods validated on bidirectional and causal architectures